
V8 под капотом / JUG Ru Group corporate blog / Habr
Ведущий разработчик Яндекс.Деньги Андрей Мелихов (также редактор/переводчик сообщества devSchacht) на примере движка V8 рассказывает о том, как и через какие стадии проходит программа, прежде чем превращается в машинный код, и зачем на самом деле нужен новый компилятор.
Материал подготовлен на основе доклада автора на конференции HolyJS 2017, которая проходила в Санкт-Петербурге 2-3 июня. Презентацию в pdf можно найти по этой ссылке.
Несколько месяцев назад вышел фильм «Последний убийца драконов». Там, если протагонист убивает дракона, то в мире исчезает магия. Я хочу сегодня выступить антагонистом, я хочу убить дракона, потому что в мире JavaScript нет места для магии. Все, что работает, работает явно. Мы должны разобраться, как оно устроено, чтобы понимать, как оно работает.
Я хочу поделиться с вами своей страстью. В какой-то момент времени я осознал, что плохо знаю, как устроен под капотом V8. Я начал читать литературу, смотреть доклады, которые в основном на английском, накопил знания, систематизировал и хочу их довести до вас.
Интерпретируемый или компилируемый у нас язык?
Я надеюсь, все знают отличие, но повторю. Компилируемые языки: в них исходный код преобразуется компилятором в машинный код и записывается в файл. В них используется компиляция до выполнения. В чем преимущество? Его не нужно повторно компилировать, он максимально автоматизирован для той системы, под которую скомпилирован. В чем недостаток? Если у вас меняется операционная система, и если у вас нет исходников, вы теряете программу.
Интерпретируемые языки – когда исходный код исполняется программой-интерпретатором. Преимущества в том, что легко достичь кроссплатформенности. Мы поставляем наш исходный код как есть, и если в этой системе есть интерпретатор, то код будет работать. Язык JavaScript, конечно, интерпретируемый.
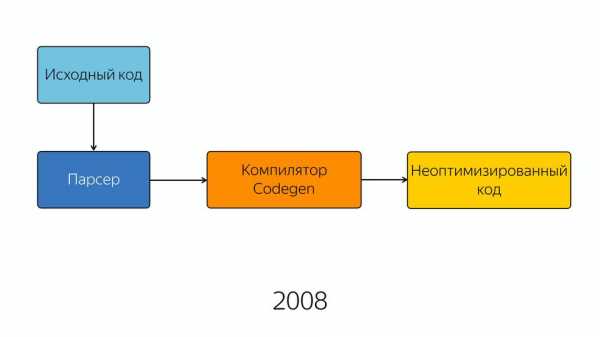
В 2008 году движок был довольно прост внутри. Ну, относительно прост — схема его была простая. Исходный код попадал в парсер, из парсера — в компилятор, и на выходе мы получали полуоптимизированный код. Полуоптимизированный, потому что хорошей оптимизации тогда еще не было. Возможно, в те годы приходилось писать лучший JavaScript, потому что нельзя было надеяться на то, что оптимизатор его сам внутри заоптимизирует.
Для чего в этой схеме нужен парсер?
Парсер нужен для того, чтобы превращать исходный код в абстрактное синтаксическое дерево или AST. AST – такое дерево, в котором все вершины — операторы, а все листья — это операнды.
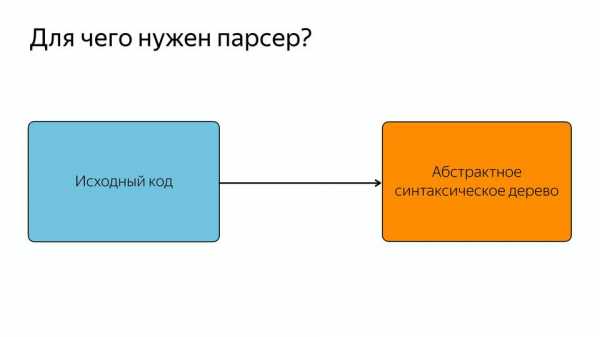
Посмотрим на примере математического выражения. У нас такое дерево, все вершины – операторы, ветви – операнды. Чем оно хорошо — тем, что из него очень легко генерировать позже машинный код. Кто работал с Assembler, знает, что чаще всего инструкция состоит из того, что сделать и с чем сделать.
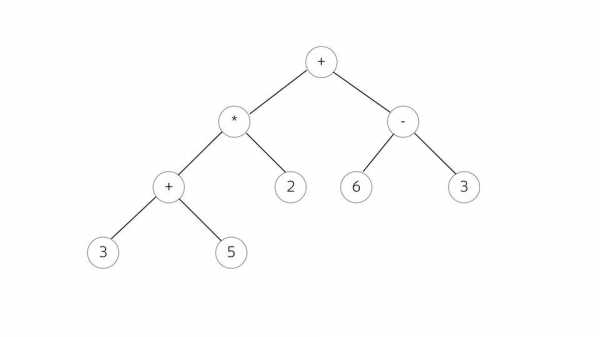
И вот здесь как раз мы можем смотреть, являемся ли мы в текущей точке оператором или операндом. Если это оператор, смотрим его операнды и собираем команду.

Что в JavaScript происходит, если у нас есть, например, массив, и мы запрашиваем из него элемент по индексу 1? Появляется такое абстрактное синтаксическое дерево, у которого оператор «загрузить свойство по ключу», а операнды – это объект и ключ, по которому мы загружаем это свойство.
Зачем в JavaScript компилятор?
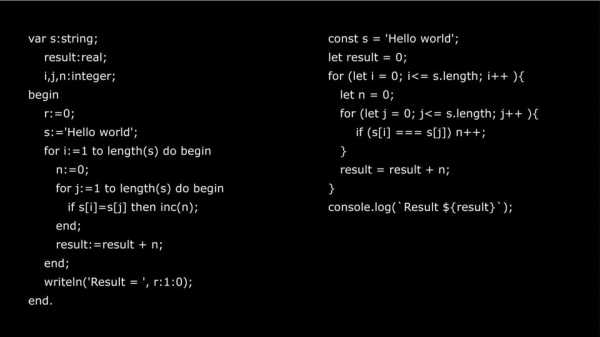
Есть один и тот же код. Один на Pascal, другой на JavaScript. Pascal — прекрасный язык. Я считаю, что с него и надо учиться программировать, но не с JavaScript. Если у вас есть человек, который хочет научиться программировать, то покажите ему Pascal или C.
В чем отличие? Pascal может быть и компилируемым и интерпретируемым, а JavaScript требует уже интерпретации. Самое важное отличие – это статическая типизация.

Потому что, когда мы пишем на Pascal, мы указываем переменные, которые необходимы, а потом пишем их типы. Потом компилятору легко построить хороший оптимизированный код. Как мы обращаемся к переменным в память? У нас есть адрес, и у нас есть сдвиг. Например, Integer 32, то мы делаем сдвиг на 32 по этому адресу в память и получаем данные.
В JavaScript нет, у нас типы всегда меняются во время выполнения, и компилятор, когда выполняет этот код, первый раз он его выполняет как есть, но собирает информацию о типах. И второй раз, когда он выполняет ту же самую функцию, он уже основываясь на данных, которые он получил в прошлый раз, предположив, какие были там типы, может сделать какую-то оптимизацию. Если с переменными все понятно, они определяются по значению, то что у нас с объектами?
Ведь у нас JavaScript, у него прототипная модель, и классов для объектов у нас нет. На самом деле есть, но они не видны. Это так называемые Hidden Classes. Они видны только самому компилятору.
Как создаются Hidden Classes?
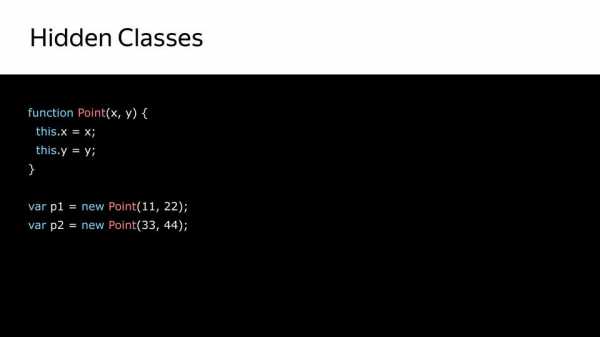
У нас есть point – это конструктор, и создаются объекты. Сначала создается hidden class, который содержит только сам point.

Дальше у нас устанавливается свойство этого объекта x и из того, что у нас был hidden class, создаётся следующий hidden class, который содержит x.

Дальше у нас устанавливается y и, соответственно, мы получаем еще один hidden class, который содержит x и y.

Так мы получили три hidden class. После этого, когда мы создаем второй объект, используя тот же самый конструктор, происходит то же самое. Уже есть hidden classes, их уже не нужно создавать, с ними необходимо только сопоставить. Для того, чтобы позже мы знали, что эти два объекта одинаковы по структуре. И с ними можно похоже работать.

Но что происходит, когда мы позже еще добавляем свойство в объект p2? Создается новый hidden class, т.е. p1 и p2 уже не похожи. Почему это важно? Потому что, когда компилятор будет перебирать в цикле point, и вот у него будут все такие же, как p1, он их крутит, крутит, крутит, натыкается на p2, а у него другой hidden class, и компилятор уходит в деоптимизацию, потому что он получил не то, что ожидал.

Это так называемая утиная типизация. Что такое утиная типизация? Выражение появилось из американского сленга, если что-то ходит как утка, крякает как утка, то это утка. Т.е. если у нас p1 и p2 по структуре одинаковы, то они принадлежат к одному классу. Но стоит нам добавить в структуру p2 еще, и эти утки крякают по-разному, соответственно, это разные классы.
И вот мы получили данные о том, к каким классам относятся объекты, и получили данные о том, какого рода переменные, где эти данные использовать и как их хранить. Для этого используется система Inline Caches.

Рассмотрим, как происходит создание Inline Caches для этой части. Сначала, когда у нас код анализируется, он дополняется такими вызовами. Это только инициализация. Мы еще не знаем, какого типа будет у нас наш Inline Caches.
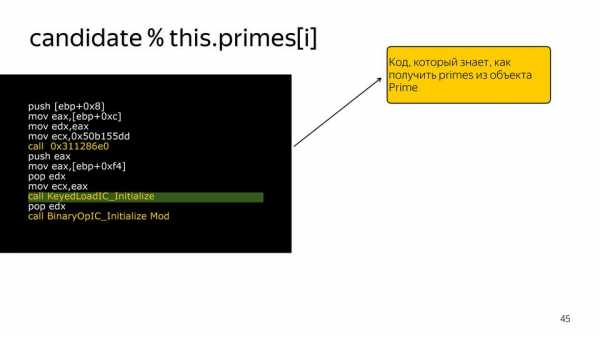
Мы можем сказать, что вот в этом месте проиницилизируй его, вот здесь загрузка this.primes:

Вот здесь загрузка по ключу:

А дальше операция BinaryOperation — это не значит, что она двоичная, это значит что она бинарная, а не унарная операция. Операция, у которой есть левая и правая части.

Что происходит во время выполнения?
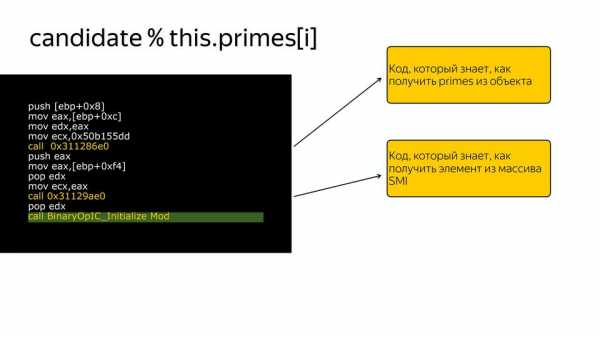
Когда код доходит, это все подменяется на кусочки кода, которые уже у нас есть внутри компилятора, и компилятор знает, как хорошо работать с этим конкретным случаем, если мы имеем информацию о типе. То есть вот здесь подменяется на вызов кода, который знает, как получить primes из объекта:

Вот здесь подменяется на код, который знает, как получить элемент из массива SMI:
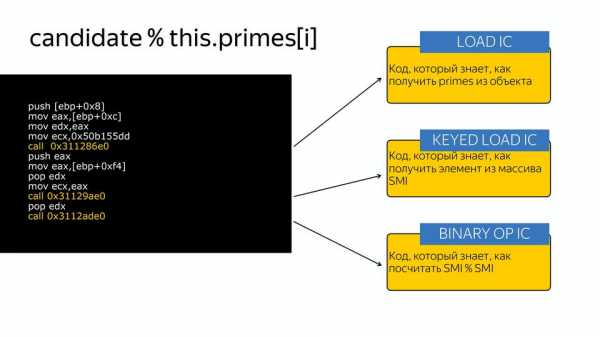
Здесь на код, который знает как посчитать остаток от деления двух SMI:
Он уже будет оптимизирован. И вот так примерно работал компилятор, насыщая такими кусочками.
Это, конечно, дает некоторый overhead, но и дает производительность.
У нас интернет развивался, увеличивалось количество JavaScript, требовалось большая производительность, и компания Google ответила созданием нового компилятора Crankshaft.
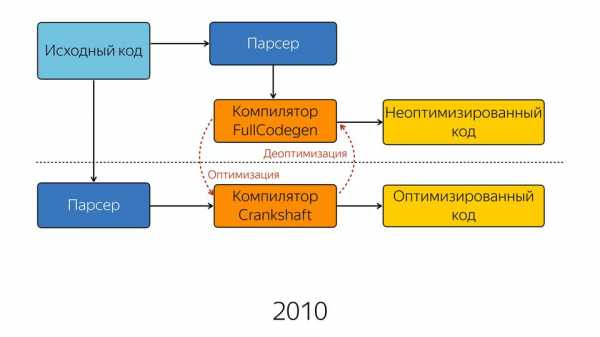
Старый компилятор стал называться FullCodegen, потому что он работает с полной кодовой базой, он знает весь JavaScript, как его компилировать. И он производит неоптимизированный код. Если он натыкается на какую-то функцию, которая вызывается несколько раз, он считает, что она стала горячей, и он знает, что компилятор Crankshaft может ее оптимизировать. И он отдает знания о типах и о том, что эту функцию можно оптимизировать в новый компилятор Crankshaft. Дальше новый компилятор заново получает абстрактное синтаксическое дерево. Это важно, что он получает не от старого компилятора AST, а снова идет и запрашивает AST. И зная о типах, делает оптимизацию, и на выходе мы получаем оптимизированный код.
Если он не может сделать оптимизацию, он сваливается в деоптимизацию. Когда это происходит? Вот как я сказал раньше, например, у нас в цикле Hidden Class крутится, потом неожиданное что-то и мы вывалились в деоптимизацию. Или, например, многие любят делать проверку, когда у нас есть что-то в левой части, и мы берем, например, длину, т.е. мы проверяем, есть ли у нас строка, и берем ее длину. Чем это плохо? Потому, что когда у нас строки нет, то в левой части у нас получается Boolean и на выходе получается Boolean, а до этого шел Number. И вот в этом случае мы сваливаемся в деоптимизацию. Или он встретил код, не может его оптимизировать.
На примере того же кода. Вот у нас был код насыщенный инлайн-кэшами, он весь инлайнится в новом компиляторе.

Он вставляет это все инлайново. Причем этот компилятор является спекулятивным оптимизирующим компилятором. На чем он спекулирует? Он спекулирует на знаниях о типах. Он предполагает, что если мы 10 раз вызвали с этим типом, то и дальше будет этот тип. Везде есть такие проверки на то, что пришел тот тип, который он ожидал, и когда приходит тип, которого он не ожидал, то он сваливается в деоптимизацию. Эти улучшения дали хороший прирост производительности, но постепенно команда, занимающаяся движком V8, поняла, что все надо начать с нуля. Почему? Вот есть такой способ разработки ПО, когда мы пишем первую версию, а вторую версию мы пишем с нуля, потому что мы поняли, как надо было писать. И создали новый компилятор – Turbofan в 2014 году.

У нас есть исходный код, который попадает в парсер, далее в компилятор FullCodegen. Так было до этого, никаких отличий. На выходе мы получаем неоптимизированный код. Если мы можем сделать какую-либо оптимизацию, то мы уходим в два компилятора, Crankshaft и Turbofan. FullCodegen сам решает, может ли оптимизировать конкретные вещи компилятор Turbofan, и если может, то отправляет в него, а если не может, то отправляет в старый компилятор. Туда постепенно стали добавлять новые конструкции из ES6. Начали с того, что заоптимизировали asm.js в него.
Зачем нужен новый компилятор?
- Улучшить базовую производительность
- Сделать производительность предсказуемой
- Уменьшить сложность исходного кода
Что значит «улучшить базовую производительность»?
Старый компилятор был написан в те годы, когда у нас стояли мощные десктопы. И его тестировали на таких тестах, как octane, синтетических, которые проверяли пиковую производительность. Недавно была конференция Google I/O, и там менеджер, управляющий разработкой V8, завил, что они отказались в принципе от octane, потому что он не соответствует тому, с чем на самом деле работает компилятор. И это привело к тому, что у нас была очень хорошая пиковая производительность, но очень просела базовая, т.е. были не заоптимизированы вещи в коде, и когда код, хорошо работающий, натыкался на такие вещи, то шло значительное падение производительности. И таких операций скопилось много, вот несколько из них: forEach, map, reduce. Они написаны на обычном JS, нашпигованы проверками, сильно медленней, чем for. Часто советовали использовать for.
Медленная операция bind – она реализована внутри, оказывается, совершенно ужасно. Многие фреймворки писали свои реализации bind. Часто люди говорили, что я сел, написал на коленке bind и он работает быстрее, удивительно. Функции, содержащие try{}catch(e){}(и finally), – очень медленные.

Часто встречалась такая табличка, что лучше не использовать, чтобы не просела производительность. На самом деле код работает медленно, потому что компилятор работает неправильно. И с приходом Turbofan можно забыть об этом, потому что все уже заоптимизировано. Также очень важно: была улучшена производительность асинхронных функций.
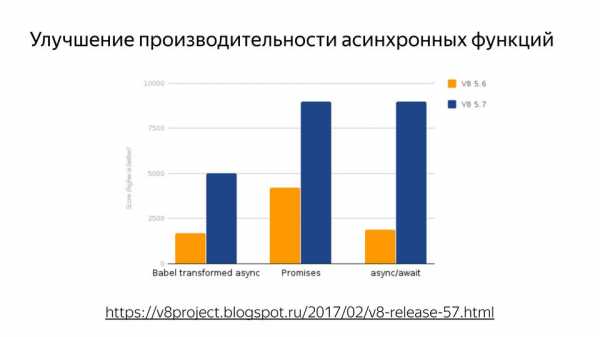
Поэтому все ждут релиза новой node’ы, которая недавно вышла, там важна как раз производительность с async/await’ами. У нас язык асинхронный изначально, а пользоваться хорошо мы могли только callback’ами. И кто пишет с promise, знают, что их сторонние реализации работают быстрее, чем нативная реализация.
Следующей была задача сделать производительность предсказуемой. Была ситуация такая: код, который отлично показывал себя на jsPerf, при вставке в рабочий код показывал уже совсем другую производительность. Но и другие такие же случаи, когда мы не могли гарантировать, что наш код будет работать так же производительно, как мы изначально предполагали.

Например, у нас есть такой довольно простой код, который вызывает mymax, и если мы проверим его (при помощи ключей trace-opt и trace-deopt – показывают, какие функции были оптимизированы, а какие нет).
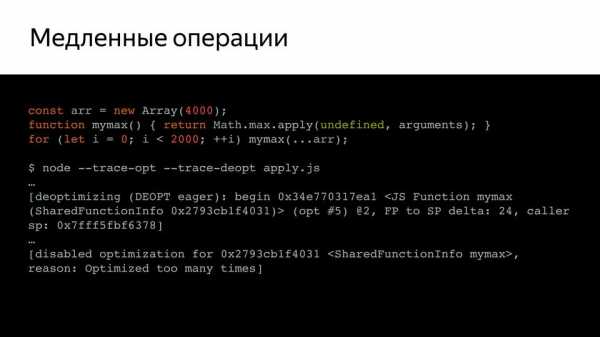
Мы можем запустить это с node, а можем и с D8 – специальной средой, где V8 работает отдельно от браузера. Она нам показывает, что оптимизации были отключены. Потому что слишком много раз запускался на проверку. В чем проблема? Оказывается, псевдомассив arguments — слишком большой, и внутри, оказывается, стояла проверка на размер этого массива. Причем эта проверка, как сказал Benedikt Meurer (ведущий разработчик Turbofan), не имела никакого смысла, она просто copypaste-ом с годами переходила.
И почему ограничена длина? Ведь не проверяется размер стека, ничего, вот просто так была ограничена. Это неожиданное поведение, от которого необходимо было избавляться.

Другой пример, вот у нас есть dispatcher, который вызывает два callback. Так же, если мы его вызовем, то увидим, что он был деоптимизирован. В чем здесь проблема? В том, что одна функция является strict, а вторая не strict. И у них в старом компиляторе получаются разные hidden classes. Т.е. он считает их разными. И в этом случае он так же уходит на деоптимизацию. И этот, и предыдущий код, он написан в принципе правильно, но он деоптимизируется. Это неожиданно.
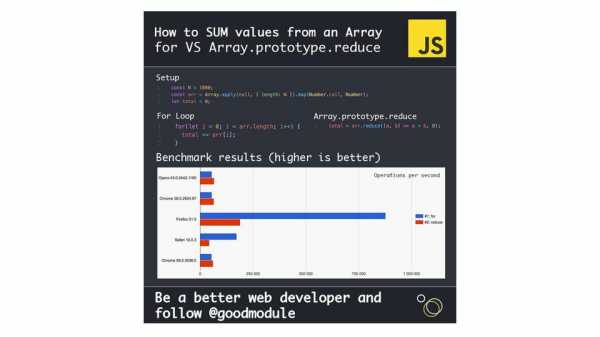
Еще был вот такой пример в твиттере, когда оказалось, что в некоторых случаях цикл for в chrome работал даже медленнее, чем reduce. Хотя мы знаем, что reduce медленнее. Оказалось, проблема в том, что внутри for использовался let – неожиданно. Я поставил даже последнюю версию на тот момент и результат уже хороший – исправили.
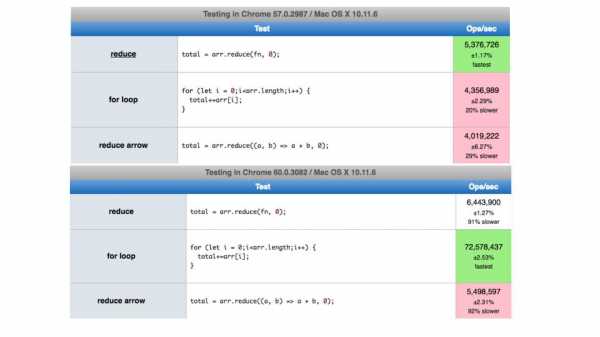
Следующий пункт был — уменьшить сложность. Вот у нас была версия V8 3.24.9 и она поддерживала четыре архитектуры.

Сейчас же V8 поддерживает девять архитектур!
И код копился годами. Он был написан частично на C, Assembler, JS, и вот так примерно ощущал себя разработчик, который приходил в команду.

Код должен легко изменяться, чтобы можно было реагировать на изменения в мире. И с введением Turbofan количество архитектурно-специфичного кода уменьшилось.
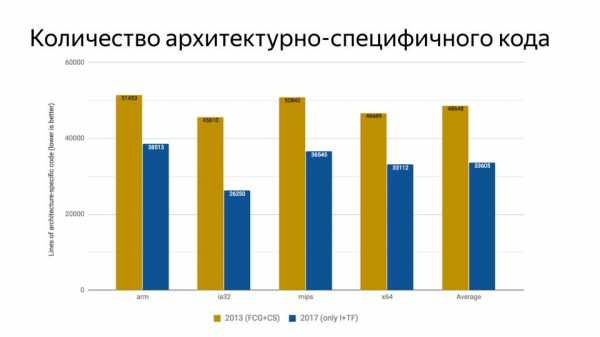
С 2013 по 2017 года стало на 29% меньше архитектурно-специфичного кода. Это произошло за счет появления новой архитектуры генерации кода в Turbofan.
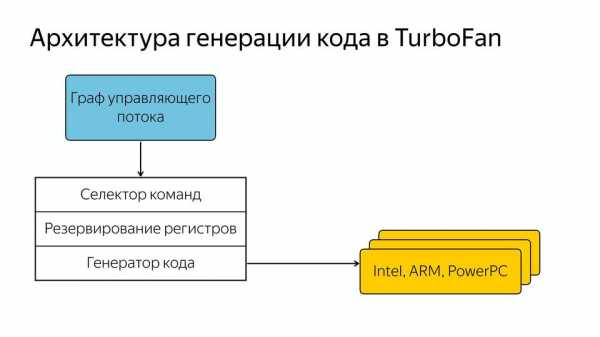
Они ее сделали управляемой данными, т.е. у нас есть граф управляющего потока, который содержит данные и знание о том, что с ними должно произойти. И он попадает в общий селектор команд, потом происходит резервирование регистров и далее генерация кода под разные архитектуры. Т.е. разработчику уже не надо знать, как написано все под конкретные архитектуры, а можно сделать более общий код. Вот так все происходило, хорошо улучшали код, но постепенно через несколько лет, после того как написали компилятор для интерпретируемого языка, оказалось, что все же нужен интерпретатор.
А в чем причина? Причину держит в руках Стив Джобс.

Это, конечно, не сам iPhone, а те смартфоны, которые породил iPhone, которые дали удобный доступ в интернет. И это привело к тому, что количество пользователей на мобильных устройствах превысило количество на десктопах.
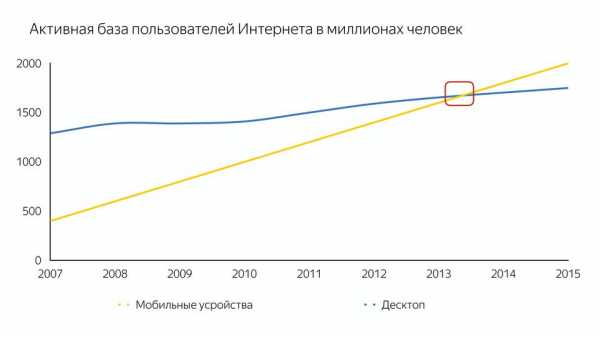
А первоначально компиляторы разрабатывались для мощных десктопов, а не для мобильных устройств.

Вот схема времени первичного анализа 1МБ JavaScript. И недавно был вопрос, почему ВКонтакте делает серверный рендеринг, а не клиентский. Потому что время, потраченное на анализ JS, может быть в 2-5 раз больше на мобильных устройствах. И это мы говорим о топовых устройствах, а люди зачастую ходят с совсем другими.
И еще одна проблема: у многих китайских устройствах памяти 512 МБ, а если посмотреть, как происходит распределение памяти V8, то появляется еще одна проблема.
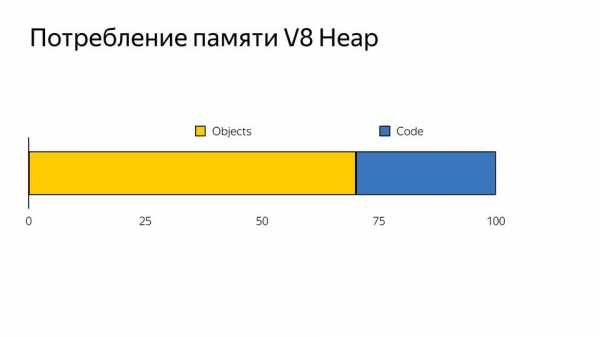
Память делится на объекты (то что использует наш код) и кодовые объекты (это то, что использует сам компилятор — например, хранит там inline caches). Получается, что 30% памяти занято виртуальной машиной для поддержки внутреннего использования. Мы не можем этой памятью управлять, ее сам компилятор потребляет.
С этим необходимо было что-то делать, и в 2016 году команда разработчиков Android из Лондона ответила созданием нового интерпретатора Ignition.
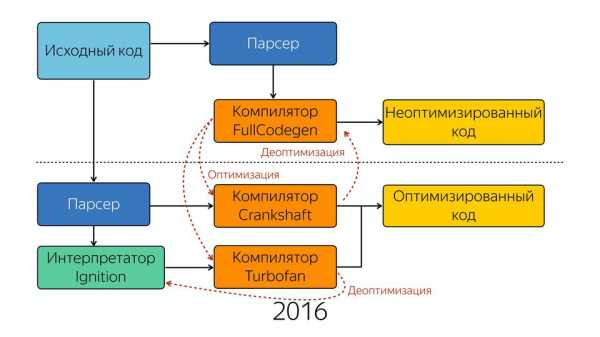
Вы могли заметить, что код, оптимизированный компилятором Turbofan, не обращается за синтаксическим деревом в парсер, а получает что-то из интерпретатора. Он получает байт-код.
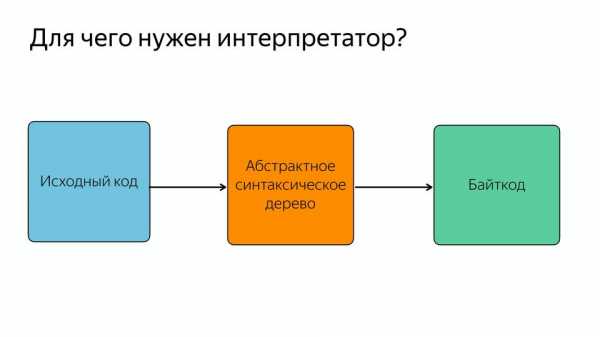
Теперь абстрактное синтаксическое дерево парсится в байт-код, и этот парсинг JavaScript происходит один раз, дальше используется байткод.
Если кто-то не знает, байткод – это компактное платформонезависимое представление программы. Это чем-то похоже на assembler, только платформонезависимый. Так он называется, потому что все инструкции занимают один байт.
Посмотрим, как для такого кусочка программы генерируется байткод.

У нас есть программа, у нас есть сгенерированный байткод и у нас есть набор регистров.
Так мы устанавливаем значения для этих регистров входные, которые попадут в нашу программу. На первом этапе мы загружаем в специальный регистр accumulator (он нужен для того, чтобы не расходовать лишний раз регистры, а участвует только в вычислениях) smi integer равный 100.

Следующая команда нам говорит, что нужно вычесть из регистра a2 (в табличке видим там 150) предыдущее значение аккумулятора (100). В accumulator мы получили 50.

Дальше нам команда говорит, что нужно сохранить в r0. Он связан с переменной d.

Дальше становится более понятно. Снова загружаем значение из b, умножаем на значение accumulator, добавляем a0 и получаем на выходе, соответственно, 105.

И вся наша программа превращается в длинную цепочку из байткода. Таким образом уменьшилось потребление памяти, которое уходило на хранение нашего кода.
Была вторая проблема, это память, которую потребляли inline caches. Для этого перешли на новые кеши – Data-driven IC, которые уменьшают стоимость медленного пути. Медленный путь – это как работает не оптимизированный код, быстрый код – когда он оптимизирован.

Слева мы видим старую схему. Когда нам нужно найти какое-либо поле в объекте, мы храним знание о том, где оно лежит в объекте, где-то храним этот объект и умеем с ним обращаться. В новой схеме существует управляющий вектор, в котором есть данные и команды, и знание о том, что с этими командами делать. И он проходит по загрузке inline caches, на быстрый путь, если деоптимизация, то на медленный путь. И, соответственно, эта схема уже не требует хранения обращений к объектам, и она получается компактней. В итоге после внедрения схемы потребление памяти на одинаковом коде уменьшилось.
И наконец в этом году схема сильно упростилась.
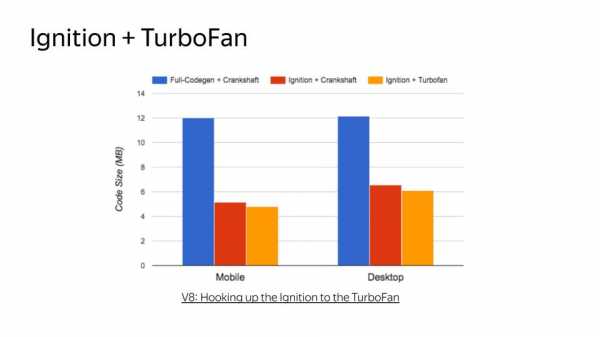
Здесь мы всегда работаем в компиляторе Turbofan. Можно заметить, что раньше компилятор FullCodegen знал весь JS, а компилятор Crankshaft — только часть JS, а теперь компилятор Turbofan знает весь JS и работает со всем JS. Если он не может оптимизировать, он выдает неоптимизированный код, если может, то, соответственно, оптимизированный. И за кодом он обращается в интерпретатор.

У нас есть классы, которые не видны (многие знают, что в ES6 есть новые классы, но это просто сахар). За ними необходимо следить, ибо код для хорошей производительности должен быть мономорфным, а не полиморфным. Т.е. если у нас изменяются входящие в функцию классы, у них меняется hidden class – у объектов, которые попадают в нашу функцию, то код становится полиморфным и он плохо оптимизируется. Если у нас объекты приходят одного типа hidden class, то, соответственно, код мономорфный.
В V8 код проходит через интерпретатор и JIT-компилятор. Задача JIT-компилятора — сделать код быстрее. JIT-компилятор прогоняет наш код в цикле и каждый раз, основываясь на данных, которые получил в прошлый раз, пытается сделать код лучше. Он наполняет его знанием о типах, которые получает при первом прогоне, и за счет этого делает какие-то оптимизации. В нем внутри лежат кусочки, которые ориентированы для работы с максимальной производительностью. Если у нас в коде есть a+b – это медленно. Мы знаем, что это number+number или string+string, мы можем сделать это быстро. Вот этим занимается JIT-компилятор.
Чем лучше оптимизация, тем выше накладные расходы (время, память). Задача же интерпретатора – уменьшить накладные расходы на память. Даже с приходом Turbofan отказались от некоторых оптимизаций, которые были ранее, потому что решили повышать базовую производительность и немного снижать пиковую.
В компиляторе есть два режима работы – холодный и горячий. Холодный, это когда наша функция запущена в первый раз. Если функция запускалась несколько раз, то компилятор понимает, что она уже горяча, и пытается ее оптимизировать. Здесь есть засада с тестами. Когда разработчики гоняют тесты по много раз и получают какие-либо данные, то это уже оптимизированный горячий код. А в реальности этот код может быть вызван один-два раза и показывать совсем другую производительность. Это необходимо учитывать.
С мономорфным кодом такой же пример. То есть когда мы пишем код, мы можем помочь нашему компилятору. Мы можем писать код так, словно у нас типизированный язык (не переопределять переменные, не записывать в них разные типы, возвращать всегда один и тот же тип).
Вот и все основные секреты.
Ссылки для чтения
github.com/v8/v8/wiki/TurboFan
http://benediktmeurer.de/
http://mrale.ph/
http://darksi.de/
https://medium.com/@amel_true
Если вы любите JS так же, как мы, и с удовольствием копаетесь во всей его нутрянке, вам могут быть интересные вот эти доклады на грядущей московской конференции HolyJS:
habr.com
характеристика, фото, схема, устройство, объем, вес. Автомобили с двигателем V8
В настоящее время существует несколько вариантов силовых агрегатов в зависимости от компоновки и количества цилиндров. Двигатель V8 относится к моторам высшего уровня для легковых машин, так как им оснащают спортивные и элитные модели. Поэтому они не сильно распространены, но востребованы.
Определение
Двигатель V8 представляет собой силовой агрегат с V-образным расположением цилиндров в два ряда по четыре и общим коленвалом.

Предпосылки создания
В начале прошедшего века не было прямой связи между объемом мотора и количеством цилиндров. Однако со временем такие факторы, как увеличение оборотов и мощности, а также стремление к снижению стоимости привели к введению среднего объема цилиндра. К тому же появилось такое понятие, как литровая мощность. Таким образом, они связали мощность двигателя с количеством цилиндров. То есть каждый цилиндр имеет определенный объем, а с конкретного значения объема снимают определенную мощность. Причем эти характеристики оптимизированы, то есть выходить за их рамки при серийном производстве невыгодно. Таким образом, небольшие массовые модели стали оснащать моторами малого объема с небольшим количеством цилиндров, а для достижения высокой мощности потребовалось создавать многоцилиндровые силовые агрегаты большего объема.
История
Первый двигатель V8 запустили в производство в 1904 г. Он был разработан двумя годами ранее Леоном Левассером. Однако его применяли не для автомобилей, а устанавливали на самолеты и небольшие суда.
Первый автомобильный двигатель V8 объемом 3536 см3 выпустила фирма Rolls-Royce. Однако она построила лишь 3 автомобиля, оснащенных им.
В 1910 г 7773 см3 V8 был представлен производителем De Dion-Bouton. И хотя автомобилей, оснащенных им, было выпущено также совсем немного, в 1912 г его представили в Нью-Йорке, вызвав большой интерес. После этого созданием таких двигателей занялись американские производители.
Первой относительно массово производить автомобили с двигателем V8 стала фирма Cadillac в 1914 г. Это был нижнеклапанный мотор объемом 5429 см3. Существует мнение, что его конструкция была скопирована с упомянутого выше французского силового агрегата. В первый год выпустили примерно 13 000 автомобилей, оснащенных им.
Через 2 года свою версию V8 объемом 4 л представил Oldsmobile.
В 1917 г Chevrolet также начал выпуск 4,7 л V8, однако, в следующем году производитель вошел в состав GM, подразделениями которого являлись и две упомянутые выше фирмы. Однако Chevrolet, в отличие от них, сориентировали на выпуск экономичных автомобилей, на которые предполагалось устанавливать более простые двигатели, поэтому производство V8 остановили.
Все рассмотренные выше двигатели устанавливали на дорогие модели. Впервые в массовый сегмент их перенесла фирма Ford в 1932 г на Model 18. Более того, данный силовой агрегат имел значительное техническое новшество. Он был оснащен литым чугунным блоком цилиндров, хотя до этого производство таких деталей некоторые считали технически невозможным, поэтому цилиндры были отделены от картера, что усложняло и удорожало их изготовление. Для создания цельной детали потребовалось усовершенствовать технологию литья. Новый силовой агрегат назвали Flathead. Его производили до 1954 г.
В США особо обширное распространение двигатели V8 обрели в 30-е гг. Они стали настолько популярными, что такими силовыми агрегатами оснащали все классы легковых автомобилей, кроме субкомпактного. А авто с двигателем V8 к концу 1970-х гг составляли 80% всех производимых в США. Поэтому многие термины, связанные с этими силовыми агрегатами, американского происхождения, а V8 у многих все еще ассоциируются с американскими автомобилями.

В Европе данные двигатели не обрели такой популярности. Так, в первой половине прошедшего века ими оснащали лишь штучно выпускаемые элитные модели. Только в 50-е гг начали появляться первые серийные восьмицилиндровые моторы или автомобили с двигателем V8. И то некоторые из последних оснащали силовыми агрегатами американского производства.
Компоновка
В начале прошлого века встречались весьма необычные для современности схемы двигателей, например, семицилиндровые, рядные восьмицилиндровые и звездообразные.
С упорядочением конструкции моторов, благодаря введению названных выше принципов, количество цилиндров было теперь определено для двигателей в зависимости от их мощности. И далее, возник вопрос об оптимальном их расположении.
Первым появился наиболее простой вариант компоновки — рядное расположение цилиндров. Такой вид предполагает их установку в ряд друг за другом. Однако данная компоновка актуальна для двигателей с количеством цилиндров не более шести. При этом наиболее распространены четырехцилиндровые варианты. Двух- и трехцилиндровые моторы встречаются относительно редко, хотя и появились еще в начале XX в. Пятицилиндровые двигатели также не особо распространены, к тому же они были разработаны лишь в середине 70-х гг. Шестицилиндровые рядные моторы в настоящее время утрачивают популярность. Рядную компоновку восьмицилиндровых двигателей перестали применять еще в 30-х гг.
Применение V-образной схемы для моторов с большим количеством цилиндров обусловлено компоновочными соображениями. Если использовать рядную компоновку для многоцилиндровых силовых агрегатов, то они получатся слишком длинными, и возникает проблема с их размещением под капотом. Сейчас наиболее распространена поперечная компоновка, а разместить рядный даже шестицилиндровый силовой агрегат таким образом очень сложно. В данном случае наибольшие проблемы возникают с размещение коробки передач. Именно поэтому такие двигатели уступили в распространенности V6. Последние можно расположить как продольно, так и поперечно.
Применение
Рассматриваемую схему чаще всего используют на двигателях большого объема. Их устанавливают в основном на спортивные и премиальные модели среди легковых автомобилей, а также на тяжелые внедорожники, грузовики, автобусы, тракторы.
Характеристики
К осноновным параметрам V8 относят объем, мощность, угол развала, уравновешенность.
Объем
Данный параметр является одним из основных для любого двигателя внутреннего сгорания. В начале истории ДВС не было никакой связи между объемом мотора и количеством цилиндров, а средний объем был значительно выше, чем сейчас. Так, известны 10 л одноцилиндровый мотор и 23 л шестицилиндровый.
Однако позже были введены упомянутые выше нормативы объема цилиндра и зависимость между объемом и мощностью.
Как было сказано, рассматриваемую компоновку применяют в основном для многолитровых силовых агрегатов. Поэтому объем двигателя V8 обычно составляет не менее 4 л. Максимальные значения данного параметра для современных двигателей легковых автомобилей и внедорожников достигают 8,5 л. На грузовики, тракторы и автобусы устанавливают более объемные силовые агрегаты (до 24 л).

Мощность
Данная характеристика двигателя V8 может быть определена на основе удельной литровой мощности. Для бензинового атмосферного мотора она составляет 100 л.с. Таким образом, 4 л мотор имеет мощность в среднем 400 л.с. Следовательно, варианты большего объема мощнее. В случае применения некоторых систем, особенно наддува, литровая мощность значительно возрастает.
Угол развала
Данный параметр актуален лишь для двигателей V-образной компоновки. Под ним понимают угол между рядами цилиндров. Для большинства силовых агрегатов он составляет 90°. Распространенность такого расположения цилиндров объясняется тем, что оно позволяет достичь низкого уровня вибраций и оптимального поджига смеси и создать низкий и широкий двигатель. Последнее благоприятно сказывается на управляемости, так как такой силовой агрегат способствует снижению центра тяжести.

Несколько реже встречаются моторы с углом развала 60º. Значительно меньше двигателей с еще более минимальным углом. Это позволяет снизить ширину двигателя, однако, на таких вариантах сложно гасить вибрации.
Существуют двигатели и с развернутым углом развала цилиндров (180º). То есть их цилиндры расположены в горизонтальной плоскости, а поршни движутся навстречу друг другу. Однако такие моторы называют не V-образными, а оппозитными и обозначают литерой B.Они обеспечивают очень низкий центр тяжести, вследствие чего такие двигатели устанавливают в основном на спортивные модели. Однако они отличаются большой шириной, поэтому оппозитные моторы встречаются редко из-за сложности размещения.
Вибрации
Данные явления в любом случае проявляются при работе поршневого ДВС. Однако конструкторы стремятся максимально снизить их, так как они не только сказываются на комфорте, но и при чрезмерном уровне могут привести к повреждению и разрушению двигателя.
При его функционировании действуют разнонаправленные силы и моменты. Для снижения вибраций необходимо уравновесить их. Одним из решений этого является конструирование двигателя таким образом, чтобы моменты и силы были равными и разнонаправленными. С другой стороны, достаточно доработать лишь коленвал. Так, можно изменить расположение его шеек и установить на нем противовесы либо использовать балансирные валы противовращения.
Уравновешенность
Прежде всего, следует отметить, что среди распространенных двигателей уравновешены лишь два типа — рядные и оппозитные, причем шестицилиндровые. Моторы прочих компоновок различаются по данному показателю.
Что касается V8, они весьма хорошо уравновешенны, а особенно варианты с прямым углом развала цилиндров и расположенными в перпендикулярных плоскостях кривошипами. Дополнительно придается плавность благодаря возможности обеспечения равномерного чередования вспышек. Такие двигатели имеют всего два неуравновешенных момента на щеках крайних цилиндров, которые могут быть полностью скомпенсированы двумя противовесами на коленвале.

Преимущества
V-образные двигатели отличаются от моторов с рядной компоновкой повышенным крутящим моментом. Этому способствует схема двигателя V8. В отличие от рядного мотора, где направление сил прямо перпендикулярно, в рассматриваемом двигателе они воздействуют на вал с двух сторон по касательной. Благодаря этому создается значительно большая инерция, придающая валу динамичное ускорение.
К тому же коленчатый вал V8 отличается повышенной жесткостью. То есть данный элемент прочнее, поэтому более долговечен и эффективен при работе на предельных режимах. А также это расширяет диапазон рабочих частот двигателя и позволяет быстрее набирать обороты.
Наконец V-образные моторы более компактны в сравнении с рядными. Причем они не только короче, но и ниже, что видно по фото двигателя V8.
Недостатки
Моторы рассматриваемой компоновки отличаются сложной конструкцией, что обуславливает высокую стоимость. Кроме того, при относительно небольших длине и высоте они широки. Также вес двигателя V8 большой (от 150 до 200 кг), что вызывает проблемы с развесовкой. Поэтому их не устанавливают на небольшие автомобили. К тому же такие моторы имеют значительный уровень вибраций и сложны в балансировке. Наконец, они затратны в эксплуатации. Во-первых это обусловлено тем, что устройство двигателя V8 весьма сложное. К тому же он имеет большое количество деталей. Поэтому ремонт двигателя V8 сложен и дорог. Во-вторых, такие моторы характеризуются высоким расходом топлива.

Современное развитие
В развитии всех двигателей внутреннего сгорания в последнее время наблюдается тенденция к повышению эффективности, экономичности. Этого достигают путем снижения объема и применения различных систем вроде непосредственного впрыска топлива, турбонаддува, изменяемых фаз газораспределения и т. д. Это привело к тому, что большие двигатели, в том числе и V8, постепенно утрачивают популярность. Многолитровые моторы теперь заменяют на турбированные двигатели меньшего объема. Это особенно коснулось версий V12 и V10, которые заменяют на наддувные V8, а последние — на V6. То есть средний объем моторов снижается, что отчасти обусловлено ростом эффективности, показателем которой является литровая мощность.
Однако на спортивных и элитных автомобилях все же используют мощные многолитровые силовые агрегаты. Причем их производительность также существенно возросла в сравнении с прошлым благодаря применению современных технологий.
Перспективы
Несмотря на перспективы замены ДВС электрическими и прочими экологически безвредными двигателями, они все еще не утратили актуальность. В частности V-образные варианты считаются весьма перспективными. К настоящему времени конструкторами разработаны способы устранения их недостатков. К тому же, по их мнению, потенциал таких силовых агрегатов не полностью раскрыт, поэтому их просто модернизировать.
fb.ru
V8 двигатель — это… Что такое V8 двигатель?
В 1910 году французский производитель De Dion-Bouton представил публике 7773-кубовый V8 для автомобиля. В 1912 году он был экспонатом выставки в Нью-Йорке, где вызвал неподдельный интерес у публики. И хотя сама фирма выпустила очень немного автомобилей с этим двигателем, в США идея V8 большого рабочего объёма «пустила корни» всерьёз и надолго.
Первым относительно массовым автомобилем с V8 стал 1914 года. Двигатель имел объём 5429 см³ и был нижнеклапанным, в первый же год было выпущено порядка 13 тысяч «Кадиллаков» с этим двигателем. GM, в 1916 году выпустил собственный V8 объёмом 4 литра. 1917 году, но в 1918 году фирма была включена в состав GM на правах подразделения и сосредоточилась на выпуске экономичных «народных» автомобилей, которым по понятиям тех лет V8 не полагался, так что производство двигателя было прекращено.
В сегмент недорогих автомобилей V8 перенесла фирма Ford с её Model 18 (1932). Технической особенностью двигателя этого автомобиля был блок цилиндров в виде одной чугунной отливки. Это нововведение потребовало значительного усовершенствования технологии литья. Достаточно сказать, что до 1932 года создание подобного двигателя представлялось многим технически невозможным. V-образные двигатели тех лет имели отдельные от картера цилиндры, что делало их изготовление сложным и дорогостоящим. Двигатель модели 18 получил название Ford Flathead и выпускался до 1954 года, когда его сменил верхнеклапанный Ford Y-BLock.
Начиная с 1930-х годов двигатели конфигурации V8 получили с Северной Америке очень широкое распространение. Вплоть до 1980-х годов версии, оснащённые двигателями V8, имели североамериканские модели всех классов, кроме субкомпактов. В частности, на конец 1970-х годов, до 80% выпущенных в США легковых автомобилей имели двигатель конфигурации V8. Поэтому двигатели V8 как правило ассоциируются именно с северо-американской автомобильной промышленностью, значительная часть терминологии так же имеет американское происхождение.
В Европе же в довоенные и первые послевоенные годы такими двигателями оснащали преимущественно автомобили высших классов, собираемые в мизерных количествах вручную. Например Tatra T77 (1934-1938) имела 3,4-литровый V8 и была выпущена в количестве всего 249 единиц[1].
В 1950-е годы в производственной программе европейских производителей премиум-сегмента появляются серийные модели с V8, например, BMW 502 или Facel Wega Excellence (последняя имела американский двигатель производства Chrysler).
Примечания
- ↑ CARS & HISTORY: TATRA T77 & T77A (1933-1938).
dic.academic.ru
Часы Smart Watch V8 — Подробный обзор и отзывы

Современные часы smart watch v8 – это умный гаджет с большим набором функций. Меню устройства простое и разобраться в нём сможет даже ребенок. Обзор на недорогой гаджет показывает, что это модное устройство, без которого не обойтись современному человеку.
Описание
Изготавливаются часы smart watch v8 в круглом корпусе. Дизайн гаджета спортивный и яркий. Производители создают модели в нескольких цветовых решениях: белый, серый, чёрный, красный и т.д. Корпус устройства полностью состоит из металла, а ремень — из полимерных соединений, придающих браслету гибкость.

С левой стороны умные часы smartwatch v8 имеют микро-разъём для подключения зарядного устройства. У входа для USB есть резиновая крышечка (на время автономной работы его нужно защищать от попадания пыли и мусора). С правой стороны находятся кнопки. Под крышкой на оборотной стороне гаджета скрывается литиевая батарея, которую в любой момент можно заменить. Здесь же расположен слот для сим-карты и карты памяти в формате микро.
Заводская прошивка гаджета предполагает 3 варианта циферблата. Для любителей классики имеется стрелочный экран, с которым гаджет смотрится очень стильно. Умные часы smart watch v8 обладают удобным и интересным меню. Чтобы воспользоваться одной из функций, необходимо подсоединиться к смартфону посредством блютуза.
Функциональные возможности
Умные часы v8 имеют большое количество функций, которые необходимы каждому современному человеку. К ним относятся:

- Осуществление вызовов и приём звонков. При сопряжении по Bluetooth, smart watch v8 выполняет функцию гарнитуры. Кроме этого гаджет можно использовать вместо смартфона, если вставить симкарту в специальный слот под задней крышкой. Если попытаться позвонить без использования телефона, то в меню появится окошко с выбором функции: звонок через смартфон или звонок через часы. В часах используется исключительно микро-симкарта. При входящем звонке исходит вибрация или звучит мелодия.
- Три сменных циферблата. В зависимости от настроения, можно установить один из предложенных вариантов.
- Собственная адресная книга. Все номера, находящиеся на микро-симкарте отображаются в часах. Можно просмотреть адресную книгу подключенного смартфона.
- Смс. Смарт часы v8 позволяют отправлять и принимать сообщения, можно подключиться к смартфону и обмениваться смсками с контактами из смартфона.
- Диктофон. Посредством данной функции можно в любой момент записать разговор или музыку.
- Аудио-проигрыватель. С его помощью можно прослушивать любимую музыку или записи, записанные на диктофон.
- Хранение файлов. Смарт часы считывают карту памяти до 32 Гб. Музыку можно хранить прямо в гаджете, без использования смартфона.
- Камера. Гаджет снабжён камерой с разрешением 0.3 MP. Изображения, полученные посредством часов можно транслировать на смартфон-андроид с помощью специального приложения.
- Калькулятор. Для современных людей данная функция лишней не будет.
- Напоминание о движении. Для тех, кто большую часть времени проводит в кабинете, эта особенность гаджета, время от времени будет подсказывать, что нужно немного размяться.
- Анти-потеряшка. Эта функция необходима тем, кто постоянно теряет из виду смартфон. Чтобы избежать потери телефона, нужно синхронизировать его со смарт-часами. Затем нужно выбрать расстояние, на котором можно находиться вдали от телефона. Когда параметры будут превышены хоть на сантиметр, смарт вотч начнет издавать звук.
- Будильник. Без утренней напоминалки не может обойтись ни один человек. А если будильник встроен в часы, то ценность его значительно возрастает.
- Календарь. Отслеживание сроков и внесение заметок на рабочую неделю — незаменимая функция.
- Отслеживание здоровья. Счётчик калорий, отслеживание сна, подсчёт шагов – важные функции для современного человека.
Благодаря большому списку функций, smart watch v8 quad band считается полезным гаджетом, способным заменить любой андроид-смартфон.
Как пользоваться часами
Перед началом использования необходимо ознакомиться с инструкцией и надеть устройство на руку таким образом, чтобы кнопка включения была справа.

Каждая кнопка в меню отвечает за определённую функцию:
- Включение-выключение, домой: если на часах стоит спящий режим, то отображается только время. Выйти из режима можно нажатием на клавишу включения.
- Подтвердить-ответить: нажав сюда, происходит переход в меню; посредством этой кнопки подтверждается действие в меню.
- Набор-меню: переход в телефонную книгу в режиме ожидания, при повторном нажатии переходит в меню. Во время вызова или прослушивания музыки можно изменить громкость.
- Назад-сбросить: отправляет к предыдущему меню, скидывается звонок.
Функции Тачскрина:
- Пролистывание меню.
- Выходит из меню, если провести пальцем сверху вниз по экрану.
Чтобы разобраться со всеми особенностями меню, потребуется уделить всего несколько минут свободного времени.
Подключение /отключение Bluetooth
Подключить и отключить блютус можно непосредственно через настройки смартфона. Все устройства, которые доступны к подключению, отобразятся на экране часов.
После того, как подключение произойдёт, на часах появится окно с запросом на разрешение чтения адресной книги и истории вызовов. Личная информация также станет доступна для просмотра. Если не нажать на согласие, то синхронизация не выполнится.
Для успешной работы расстояние между двумя устройствами не должно быть больше 10 метров. При несоблюдении этого правила, smart watch v8 и смартфон потеряют связь в автоматическом режиме через несколько минут.
Как действовать после успешного подключения устройства
Телефонная книга успешно синхронизируется. Теперь можно её просматривать. Чтобы это сделать, нужно нажать на копку Набор-Меню и выбрать нужный пункт. Затем нажмите на вызов. Постарайтесь не заслонять микрофон и динамик. На часах можно свободно просматривать входящие и исходящие сообщения. Различные оповещения, приходящие на смартфон, отображаются на экране часов.

Смс из соцсетей посредством Bluetooth перенаправляются на умные часы smartwatch v8 . Через блютуз можно слушать любимые треки. Громкость и песни переключаются с помощью кнопок в нижней части часов. Таким же способом управляется камера смартфона.
Шагомер работает только в том случае, если человек с часами на руках идёт ровной походной. Это необходимо для поддержания здоровья. Количество пройденных шагов отображается на экране слева внизу. Справа отображаются метры. Внизу прописываются потраченные калории. Вверху можно изменить настройки. После каждой прогулки нужно сбрасывать подсчитанные шаги. Сделается это нажав на кнопку «Reset pedometer».
Если связь между телефоном и часами прервётся, то на экране наручного гаджета появится оповещение. В настройках часов smart watch v8 можно поменять язык, а также просмотреть информацию об уровне заряда. При необходимости можно использовать порт для зарядного устройства в качестве USB.
Видеообзор
smart-planets.ru